Our migration from kops to EKS
EKS in a Terraform way
Introduction
This article will focus on several design decisions we made adopting EKS into our existing Terraform based Infrastructure management. Some of the main reasons for us to consider EKS were:
- Ability to adopt latest Kubernetes releases and patches with less effort through a managed solution
- Worry less about the Kube control plane and etcd configuration (etcd-manager introduced with kops 1.12 made necessary security changes, requiring a significant investment in reviewing our core cluster components to ensure a smooth upgrade - we wanted to simplify this upgrade process)
- Potential cost savings in regards to the control plane, less operational overhead as well as moving from 100% RI / onDemand workers to include Spot Instances
To wet your appetite, here are some initial conclusions after we completed our migration:
- in kops our CoreOS nodes would be ready for cluster workloads in about 3-5 minutes after being created
- in EKS, using the pre-baked Amazon Linux 2 amis for EKS, our worker nodes are ready for cluster workloads in just about 1 minute after the scale-up event
- We have 70% savings using mixed spot instances:
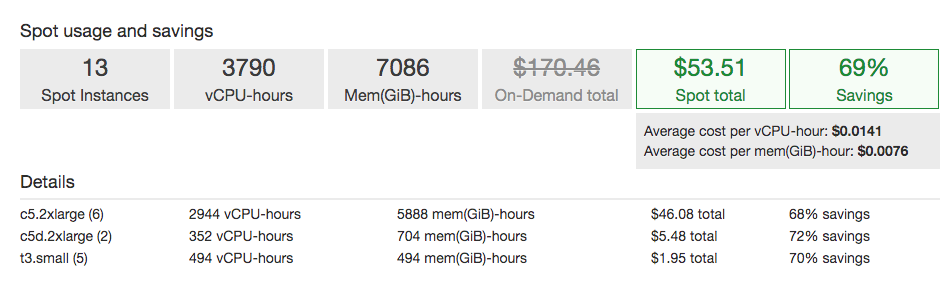
Spot Savings
Background
Personally I have been running Kubernetes on AWS using kops since 2017 (using pure Terraform before that). I shared early 2018 how we used kops bootstrapping in a presentation before I joined swat:
End of 2018, I shared how we used kops templating at swat as well as how we were using several nodeGroups for security reasons:
In both cases, kops generated a Terraform module and provides node provisioning for us, which we were able to extend and hook into for customizations.
EKS Cluster admin access best practice
Initial Google searches surfaced the great eksworkshop and Hashicorp’s own intro to EKS.
However, neither of these resources highlighted the importance of paying close attention to the AWS account provisioning the EKS cluster (or we missed the warnings). As such I wanted to highlight how we decided to create an AWS IAM role in Terraform specifically for creating EKS clusters, ensuring a select group of people could assume this role to take full ownership of a cluster.
We first need to define the required permissions to provision EKS clusters (this includes the ability to pass account roles to the EKS service from Amazon)
Next we need to allow users in our account to assume this role by making the role trust the current account
Finally, we create an IAM Group, so we can manage which users can assume this eks role based on their group membership
To create the EKS cluster using Terraform, first create the cluster specific IAM roles and security groups following the Hashicorp documentation.
Every EKS cluster, however, should now be created using this IAM role (we use terraform remote state to pass the role ARN here)
Cluster admins can now gain Kubernetes access using the following command
aws eks --region ${AWS_REGION} update-kubeconfig --name ${CLUSTER_NAME} --role-arn ${EKS_ROLE_ARN} --alias ${CLUSTER_CTX}
kubectl --context ${CLUSTER_CTX} cluster-info
EKS references and initial exploration
The EKS workshop mainly relies on eksctl a tool initially developed by weaveworks, but adopted by AWS and with a significant amount of contributions by a growing community. The eksworkshop provides a sample CloudFormation template specifically to run spot Instances - at the time of writing, the Hashicorp documentation did not detail how to set up mixed instance autoscaling groups.
To fit EKS into our existing Terraform based workflow, we mixed the Hashicorp terraform code with a single autoscaling group of workers managed by CloudFormation:
As we were adding different type of workers, some of which we did not want to autoscale, we had the need to customize the CloudFormation template so we forked it and push it to our own s3 bucket as follows:
Here is an example of the initial changes we were making:
Using this custom template the Cloudformation Terraform resource instead
Here are the final results applying the above diffs for the CFN template and TF config
At this stage we re-evaluated our decisions to use CloudFormation stacks managed by Terraform:
- kube-aws / eksctl / … - are all tools which render CloudFormation templates based on common flags and deployment scenarios
- There is a big community managing ekstcl adding configuration flags and implementing best practices into the CFN templates
- CloudFormation has the ability to manage rolling updates fully from the AWS side, it has the ability to handle phases with nodes signaling the stack about the progress
Struggles:
- We had to learn CloudFormation while using Terraform for all our other infrastructure (both on AWS and not on AWS)
- Terraform managing CloudFormation stacks is not ideal, perhaps due to our inexperience we ended up having to refresh the CFN stacks through the console for certain template changes
We either had to adopt eksctl or manage our autoscaling groups fully with Terraform.
We felt the eksctl workflow did not suit our needs and decided to further explore mixed instance autoscaling EKS workers managed by Terraform.
Mixed instance autoscaling EKS workers managed by Terraform
To achieve this, we had to translate the CFN stack to Terraform, this consists of:
- The Instance user-data which allows some configuration of the EKS node boostrapping script
- The newer generation LaunchTemplate
- The AutoScalingGroup with mixed instance policies
- AutoScaling lifecycle hooks used to handle scaling events
To make the boostrapping configurable depending on the type of workers, we decided to template the user-data script:
Once templated, we render it in terraform as follows
The launch template is very straight forward
The Autoscaling group with mixed instance policies and LifeCycleHooks required the most time to fully grasp
Handling multiple types of EKS workers
Using kops, you run certain components on the master nodes, these have instance profiles with higher permissions. Relying on kube2iam / kiam, may cause unexpected failures when the sts token retrieval is delayed. Zalando has a work around, but it is very invasive, requiring you to fork community maintained components. As such we decided to create a set of “System” nodes which have higher permissions. Use taints, labels and tolerations to restrict cluster components to these system nodes. These system nodes have custom IAM Profiles, different taints & labels, different instance types as well as different kube reserved resources.
Additionally, our cluster ingress started to be heavy handed with an in-house developed API Gateway tagged on, as a result we decided not to run it as DaemonSet on every node any more and dedicating a set of “Edge” nodes (again using taints & labels to control the workloads). As we moved to NLBs, we wanted only these “Edge” nodes to allow ingress through the NLBs into our private subnets. These edge nodes have different security groups from all other nodes, different taints, different instance types and system reserved reservations.
NOTE: At the time of writing, the main concern about using privileged instance profiles and taints, may be due to Kubernetes not having role based access control to tolerate certain taints. Custom admissions hooks maybe a way to prevent end users from running workloads on these privileged nodes and may be explored in the future.
As we were still on TF 0.11, creating TF Modules to handle all the configuration differences mentioned above didn’t seem viable. We heavily use coveo/gotemplate for these scenarios as we are mostly familiar with gotemplates due to Helm.
We decided on the following structure to capture the differences in our worker configurations:
To generate the necessary tf resources based on a list of worker configurations, we use the following workers.tf.template
We now have autoscaling groups fully managed in Terraform. The next problem is to handle rolling updates. Kops has built-in processes to cordon, drain and replace worker instances. Eksctl orchestrates this through CloudFormation as well.
In the Terraform landscape, a great tool to roll nodes in an autoscaling group is palantir/bouncer. We helped add initial support for LaunchTemplates and will detail the necessary steps to integrate it for EKS workers in the following sections.
Node maintenance, Autoscaling and LifeCycleHooks
As hinted in the previous section, orchestrating nodes during maintenance involves several repetitive commands. Additionally, scaling events outside our control require some of these operations to be fully automated based on events.
A great architectural pattern is to use AWS Lambda functions to handle these events:
- Drain nodes based SpotInstance Termination event
- Drain nodes based on autoscaling instance termination event
The eksworkshop details how to handle spot Instance terminations by having each instance query the EC2 metadata endpoint in a loop. Alternatively, since January 2018 these events are available through CloudWatch event rules - a sample implementation is available via awslabs/amazon-eks-serverless-drainer.
At this stage, we discovered the aws-samples/amazon-eks-refarch-cloudformation by @pahudnet and wish we had found it earlier.
A lot of great work is being put into AWS CDK with an promising module for EKS although all of this was still experimental at the time of this writing.
As we provisioned our EKS clusters with Private APIs and had some concerns if it would be easy to use lambda in our scenario we decided instead to use rebuy-de/node-drainer over the more popular aws-kube/node-drainer-ds.
rebuy-de/node-drainer relies on SQS to deliver ASG Instance termination events. To configure this we needed to create an SQS queue, give our system workers ability to read from the queue and configure our LifeCycleHooks to publish events to the queue.
First we create a Queue and allow AWS Autoscaling service to publish messages to this queue
Next, we allow our system workers IAM profile to read message from the same queue
NOTE: The above policy ensures the system workers of 1 cluster can not accidentally modify autoscaling groups from other clusters as well as ensure the rebuy-de/node-drainer has the ability to resolve instance-id to kube node-name.
Finally, we add the sqs target arn to our workers into our template ([final template]()):
